In-memory caching
The in-memory caching system is designed to increase application performance by holding frequently-requested data in memory, reducing the need for database queries to get that data.
The caching system is optimized for use in a clustered installation, where you set up and configure a separate external cache server. In a single-machine installation, the application uses a local cache in the application's server's process, rather than a cache server.
Note: Your license must support clustering in order for you to use an external cache server.
Parts of in-memory caching system
In a clustered installation, caching system components interoperate with the clustering system to provide a fast response to client requests while also ensuring that cached data is available to all nodes in the cluster.
- Application server: The application manages the relationship between user requests, the near cache, the cache server, and the database.
- Near cache: Each application server has its own near cache for the data most recently requested from that cluster node. The near cache is the first place the application looks, followed by the cache server, then the database.
- Cache server: The cache server is installed on a machine separate from application server nodes in the cluster. It's available to all nodes in the cluster. Note that you can't create a cluster without declaring the address of a cache server.
- Local cache: The local cache exists mainly for single-machine installations, where a cache server might not be present. Like the near cache, it lives with the application server. The local cache should only be used for single-machine installations or for data that should not be available to other nodes in a cluster. An application server's local cache does not participate in synchronization across the cluster.
- Clustering system: The clustering system reports near cache changes across the application server nodes. As a result, although data is not fully replicated across nodes, all nodes are aware when the content of their near caches must be updated from the cache server or the database.
How in-memory caching works
For typical content retrievals, data is returned from the near cache (if the data has been requested recently from the current application server node), from the cache server (if the data has been recently requested from another node in the cluster), or from the database (if the data is not in a cache).
Data retrieved from the database is placed into a cache so that subsequent retrievals are faster.
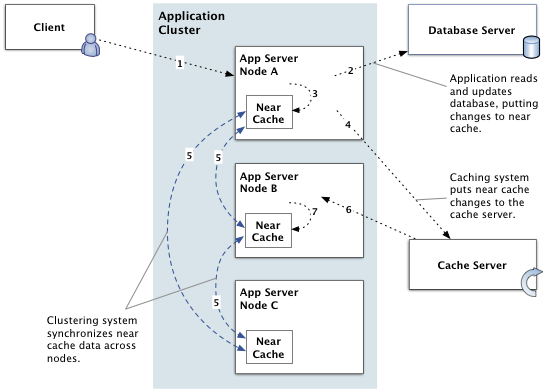
Here's an example of how changes are handled:
- Client makes a change, such as an update to a user profile. Their change is made through node A of the cluster, probably via a load balancer.
- The node A application server writes the change to the application database.
- The node A app server puts the newly changed data into its near cache for fast retrieval later.
- The node A app server puts the newly changed data to the cache server, where it will be found by other nodes in the cluster.
- Node A tells the clustering system that the contents of its near cache have changed, passing along a list of the changed cache items. The clustering system collects change reports and regularly sends them in a batch to other nodes in the cluster. Near caches on the other nodes drop any entries corresponding to those in the change list.
- When the node B app server receives a request for the data that was changed, and which it has removed from its near cache, it looks to the cache server.
- Node B caches the fresh data in its own near cache.
Cache server deployment design
In a clustered configuration, the cache server should be installed on a machine separate from the clustered application server nodes. This way, the application server process is not contending for CPU cycles with the cache server process. It is possible to have the application server run with less memory than in a single-machine deployment design. Additionally, it is best if the cache servers and the application servers are located on the same network switch to reduce latency.
Choosing the number of cache server machines
A single dedicated cache server with four cores can easily handle cache requests from up to six application server nodes running under full load. All cache server processes are monitored by a daemon process that automatically restarts the cache server if the JVM fails completely.
In a cluster, the application continues to run even if all cache servers fail; however, performance degrades significantly as requests previously handled via the cache are transferred to the database, increasing its load.
Adjusting near cache memory
The near cache, which runs on each application server node, starts evicting cached items to free up memory once the heap reaches 75 percent of the maximum allowed size. When factoring in application overhead and free space requirements for efficient garbage collection, a 2GB heap means that the typical amount of memory used for caching will not exceed about 1GB.
For increased performance, larger sites should increase the amount of memory allocated to the application server process. Monitoring GC logs or other tools can help determine if memory usage consistently remains at or above 70 percent, even after garbage collection.
Adjusting cache server memory
The cache server process operates similarly to the near cache. However, it initiates eviction once the heap reaches 80 percent of the maximum amount. On installations with large amounts of content, the default allocation of 1GB to the cache server process may not suffice and should be increased.
To adjust the cache server's memory usage, set the cache.jvm_heap_max and cache.jvm_heap_min values, as shown in the following example:
jive set cache.jvm_heap_max 2048
jive set cache.jvm_heap_min 2048
Note that you should set the minimum and maximum values to the same amount to prevent premature evictions. For additional memory, recommended values are 2048 (2GB) or 4096 (4GB). Restarting the cache server is required for these changes to take effect.
References
- In-memory caching overview Here you can find general information about how in-memory caching works in Jive.
- Managing in-memory cache servers Here you can find information on how you can manage the cache server nodes in a cluster, including starting and stopping servers, adding and removing nodes, and moving a node.
- Configuring In-Memory Caches When configuring cache servers, give each server the list of all cache server machines.
- Troubleshooting caching and clustering This topic lists caching- or clustering-related problems that can arise, along with tools and best practices.